
disParity is another free snapshot RAID design. It is a command line utility, though the latest beta does have a GUI. disParity can be used on drives that already contain data, and it does not lock in the data. This sets it apart from more native solutions like RAID, ZFS, and Storage Spaces. You can start using it, and then stop using it, at any time. It can also run parity across network drives. I have a hard time imagining why this would be necessary. I suppose if you had a USB drive plugged into a router, you could include it with parity protection.
Ease of Use

disParity 0.21 Command
disParity uses a simple command line interface. I did not find documentation to be necessary to figuring out how to use the utility, but it also doesn’t do anything for you automatically. Since it’s command line, it would not be difficult to wrap scheduled activities and batch processes around it, which is the only way anything is going to happen automatically. It does no reporting on its own, however it does have validation capabilities that could be included in a scheduled script.
Performance
Since disParity is a snapshot raid utility, it does not affect performance in any way unless it is running. When running, it does hit the CPU pretty hard, but memory usage is surprisingly low considering the amount of data it is processing. I never observed memory usage above 20MB. It does not appear to be bound to a single core, but it did seem to max out at 25% on the Phenom II X4 945 @ 3Ghz. Most of the time usage appeared around 20-22%.
Since disParity does not run in real time, a typical benchmark won’t tell us anything. So, I filled some drives with data and ran some tests. disParity requires a separate drive for parity, rather than spreading it across the existing drives like RAID 5. I had four 3TB drives, three are marked as data and one as parity.
Drive 1: 1.23TB
Drive 2: 1.19TB
Drive 3: 0B
Parity: 1.21TB
I was surprised to see the Parity drive use less space than the largest drive. My assumption here is just efficient disk usage, since it writes exactly 1GB data files which would avoid all of the lost space at the end of sectors.
Initial parity: ~10 hours
Update (no change): Near Instant
Add 28k file on Drive 3: Near Instant
Undelete 28k file on Drive 3: Near Instant
Rebuild Drive 1: ~4 hours
Rebuild Drive 2*: ~3.5 hours
Update after Add 3.5GB to Drive 2 (15,713 files): ~42 minutes
Update after Remove 20GB from Drive 1 (4025 files): ~6.5 minutes
At this point, Drive 1 and 2 each contain 1.19TB. The parity drive contains 1.21TB. The difference is small and when adding new files it is brought back down to slightly below the largest data drive level. This could lead to a situation where the parity drive is full before the data drives, but this risk seems small.

disParity 0.21 Recovery Fail
*In this test I deleted everything from Drive 3 and 2 files from Drive 1 after the recovery was started. This caused a fatal error with a stack dump prior to completion. I then tried to recover again, which did not resume and simply started over. Another fatal error was encountered on file access on the recovered drive, presumably a recovered file that failed to complete. Deleting all contents of Drive 2 and restarting the process did a successful recovery of all but 6 file. Unfortunately, there is no summary output at the end except that there were 6 failures. I can review the log in the disParity folder and look for the keywords “Verify FAILED”.
Memory usage stayed surprisingly low at around 20MB or less most of the time, but spikes near 50MB were observed times when accessing large amounts of small files. This is most likely the result of the garbage collection process in the .NET framework. . Processor usage was mostly around 20-23%. It appears to be limited to one core, so there may be room for improvements in the future. Disk IO did not appear to be a bottleneck based on Resource Monitor observations of 5-20MB/s..
disParity 0.31/0.32 (GUI)
The GUI can easily import the configuration and data from earlier versions, and it does provide a nice UI.It does use considerably more memory though. Memory usage seems to be in the 40-50MB range most of the time, with observed spikes over 150MB. Version 0.31 has temporarily disabled command line support. It also failed to update when doing adds or deletes on the data drives. Fortunately, the command line version can still update the same parity data.
 disParity 0.31 Changes |
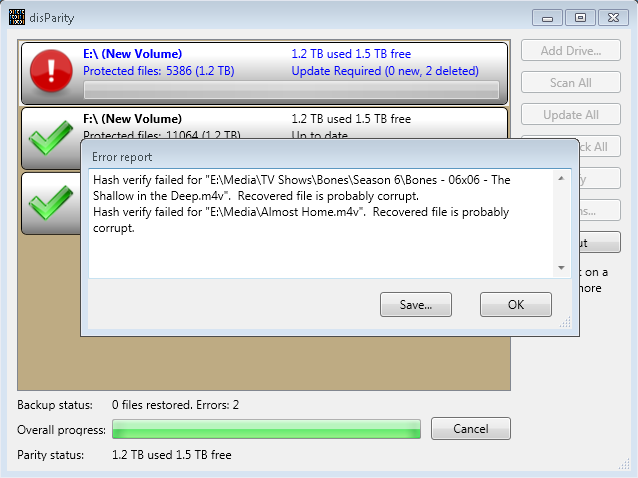 disParity 0.31 Recovery Failed |
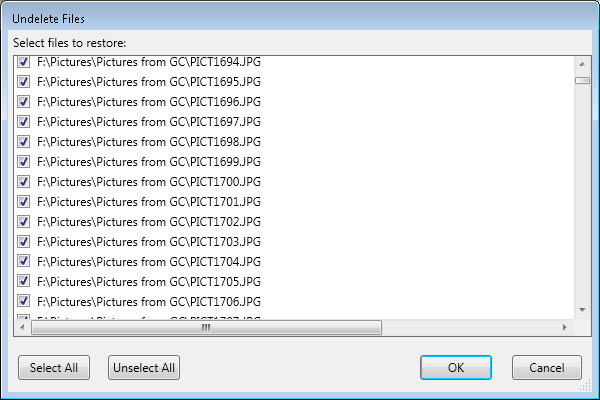 disParity 0.31 Undelete |
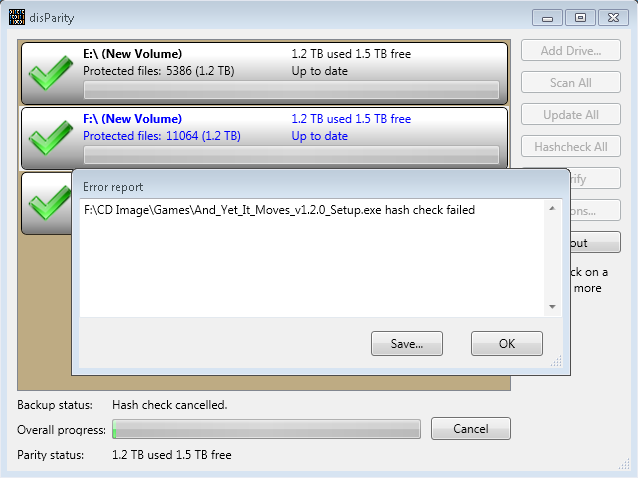 disParity 0.31 Verify Failed |
Verdict
Ease of Use: 3/5, Nothing is automated.
Drive loss limit: 1
Performance: 3/5, No impact on read/write, but can be significant when updating / recovering. Room for improvement in multi-threading.
Expansion / Upgrade options: Functional. Add drives to Parity or replace drives simply by copying contents and updating config (if necessary).
Efficiency: N-1
Cost: Free
Viable: No.
I don’t consider this viable for a dedicated file server solution, but as a free option for some data redundancy of data that is not facing changes, this may be an option for some. Mostly this seems like a curious research project at this stage, but that’s also how the highly successful LAME project was started.