
SnapRAID falls under the Snapshot RAID class of redundancy. It functions very similar to disParity. SnapRAID is a GPL3 open source, cross platform solution. It also has the optional capability of supporting a RAID6 model of dual disk parity, allowing it to recover from up to two disk failures..
It is still a snapshot parity solution. Because of this, it is not suitable for real time redundancy. However, it may be perfectly suitable for media libraries and other large file sets that infrequently change and that aren’t mission critical.
Ease of Use
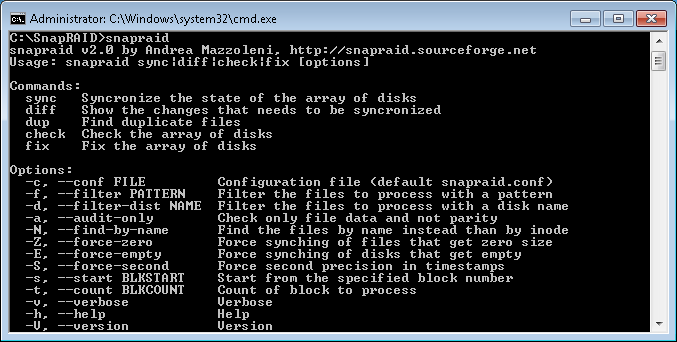
SnapRAID Command Line Arguments
The basic functionality of SnapRAID is pretty simple. Starting with the config, you define a parity location, q-parity (optional, for RAID6 like dual disk parity), content, and disks. As one would expect from an open source solution, there are some other options for those that like to tweak things that nobody should ever care about. I never did really figure out why I was defining the content file locations, but it’s just a file that SnapRAID will create. The folder destinations must exist or an error will be thrown. Now, simply run the command “SnapRAID sync” and the process will begin.
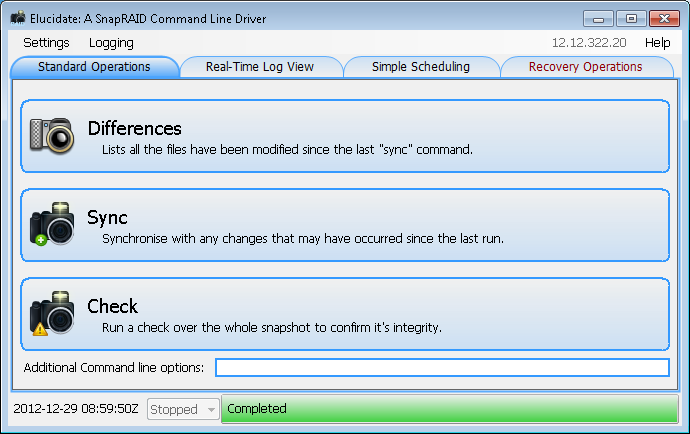
Elucidate GUI
Elucidate is a GUI front end to the command line utility, and may help less technical users. It also has a simple scheduled task interface to create a sync task. By default, this runs shortly after the administrator logs on. I would think this would make more sense to run nightly, or at least weekly, as a server environment will see very few log ons.
Recovery can be done simply by running “SnapRAID fix”, or optionally passing in parameters for what files should be restored.
One thing I saw that I did not like was that it was excluding “system” files, like Folder.jpg and the GUID named album art files in music directories. My first thought was that it was making decisions based on Thumbs.db being excluded, so I removed that from the exclusions list. It is included in the config file by default. When doing the next sync, it still ignored these files. Most of these files will be automatically restored by iTunes and Windows Media Player or others, however some I have manually placed due to automated systems not finding them, or finding the wrong ones. I really don’t like that it was attempting to exclude these files that did not obviously match an exclude mask.
On the contrasting side of that is a feature I really liked. “SnapRaid dup” will identify all duplicate files in the array in seconds. I hadn’t thought of it before, but it makes sense to include this feature. Hashes and file sizes are already stored, so it’s pretty easy to to print out a list. In my ~3TB of collective data on these drives, 4,555 duplicates were found accounting for about 20GB of space. This list was returned in well under one minute.
Performance
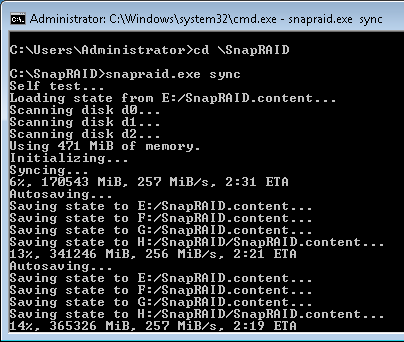
SnapRAID Sync Execution
As a snapshot solution, SnapRAID will not impact read or write performance either positively or negatively. So, the only real concern is how well does it perform when it needs to do things. For this I filled some drives with random files and put it through some simple tests. A memory footprints of nearly 500MB were maintained through all operations, which appears to be somehow targeted based on start up output. This implementation appears to be single threaded and would utilize most of a single core during processing.
Drive 1: 1.31TB
Drive 2: 1.19TB
Drive 3: 0B
Parity: 1.21TB
As with disParity, the parity drive used less than the largest data drive.
Initial parity: ~3 hours
Update (no change): < 1 minute
Add 28k file on Drive 3: < 1 minute
Undelete 28k file on Drive 3: < 1 minute (~ETA 3 hours with no arguments)
Rebuild Drive 1: ~7 hours
I didn’t throw all the curve balls at this solution as I did at disParity. disParity was able to handle them, and I’m sure SnapRAID will too. While the initial parity build was significantly faster, the rebuild was significantly slower. disParity works on file level checksums, and SnapRAID works on the block level. As I watched it rebuild, I saw it building out the same file for large periods of time as it did each segment of the file. One thing that really disheartened me was once the rebuild was complete. I assumed I would be able to continue using it as it was a healthy array again, but upon running a sync it informed me the drive had changed or been rebuilt, and I must force it to rebuild the array. This was estimated to take about 3 hours again.
Verdict
Ease of Use: 2/5, Nothing is automated, logs and summaries are limited
Drive loss limit: 1 (or 2)
Performance: 3/5, No impact on read/write, but can be significant when updating / recovering. Room for improvement in multi-threading.
Expansion / Upgrade options: Functional. Add drives to Parity or replace drives simply by copying contents and updating config (if necessary).
Efficiency: N-1 (or N-2)
Cost: Free / GPL3
Viable: No.
As with disParity, I don’t consider this a viable option for a file server that is expected to have redundancy. As a means to add some parity redundancy to existing drives or any type, this solution is capable of providing some security.